DIRECTOR'S REPORT (MAR '10): Debrief Part 2: Technical Detail and Future Systems
Technical Detail: Original System Architecture: Single Replicated Pair
In 2007 we started to plan our next generation of data storage. We wished to have a resilient and replicated system that enabled us to not rely on any one machine staying up
We went for a dual system configuration using a technology called DRBD (http://www.drbd.org/). Each storage system would run several large disks in a RAID 5 (allowing any single disk to fail without affecting the system) and be replicated in near-real-time to the second server. All access servers would be able to access these servers via a network file system (NFS).
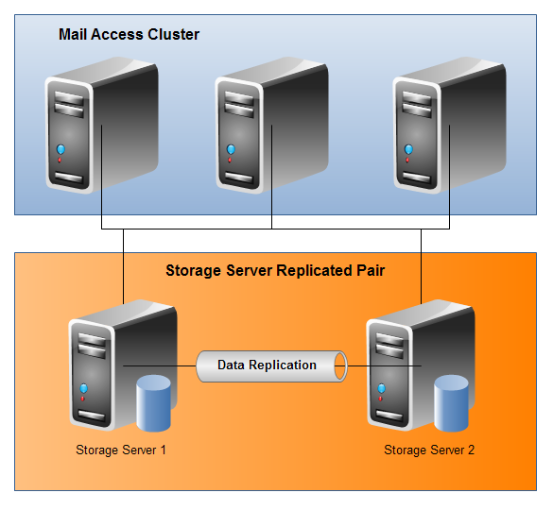
Each server would have its storage stored as two slices, A and B. Server 1 would run Slice A as the primary and replicate Slice A to Server 2 who would hold that data on standby. Likewise Server 2 would run Slice B as primary, replicating to Server 1.
Should any server experience a total failure, we would be able to mount the standby slice and point all access servers to the backup server for both Slices. Once we repair the first server we can then move the slice back and continue operation as normal.
The downsides to this system is that any storage failure would require manual intervention to bring up the backup slice and repoint the access servers. Additionally, the final restore phase of moving the backup slice back to its original server would require some additional maintenance downtime. The work would take only a matter of minutes but any downtime at all was something we wished to avoid.
When this system started to reach its capacity in Autumn of 2009, we started to investigate a solution that would not require such off-line maintenance periods and decided to test out a Storage Area Network (SAN) solution.
In 2007 we started to plan our next generation of data storage. We wished to have a resilient and replicated system that enabled us to not rely on any one machine staying up
SAN Storage Architecture: “Highly reliable” solution
By the end of 2009 we had spent over two months testing the performance and reliability of a HP SAN solution provided by our Data Centre providers. Throughout this time the SAN performed flawlessly and never experienced any outages whatsoever.
The idea behind a SAN is that it is a very very reliable system that you can depend on. We regularly heard phases such as ‘never fail’ in our investigations of SAN systems and this gave us confidence that this would be the right solution for us. The SAN isn’t just one machine but a network of machines presented as one. Our mail access cluster only had to have knowledge of a single point of connectivity but in reality this was split across 4 highly powered storage servers. If any of those servers went down the SAN was designed so that we wouldn’t be affected so no downtime would be necessary.
Network Diagram of SAN System:
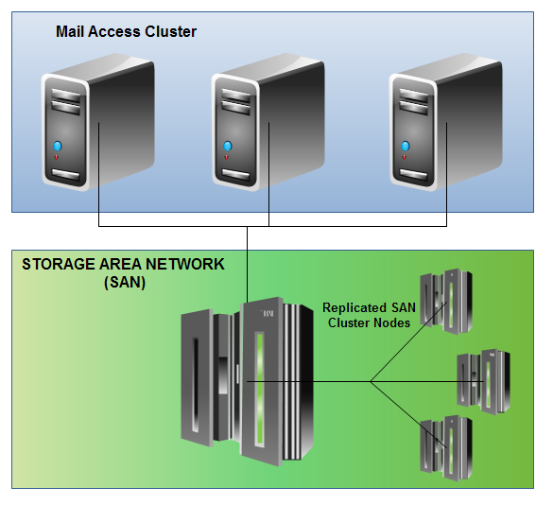
In December we decided to ‘pull the trigger’ and set our migration scripts into action. These were designed to run 24/7 and most of you will not have noticed your account move as they intelligently worked around when you were online. Throttled right down the entire migration would have taken several months and was about 80% complete when the SAN system failed.
It is now clear that the problem was that one of the nodes had ‘semi-failed’. If the node had completely failed we would have been absolutely fine. The problem is that with this partial failure, the node was kept active in the cluster and dragged performance down.
There is obviously a flaw in the monitoring system which must be corrected before we would trust our user’s data to this system again. Our Data Centre management have told us that should this happen again they would be able to detect and correct the problem within minutes rather than days but we have decided to allow their system to mature before we consider using it for mission critical use.
Future System: Multiple Replicated Pairs
During the outage, our priority was to restore access as soon as possible. Moving back to the two original servers was out of the question as they had already started to struggle with the load before the migration and we had grown since then.
Instead, we activated two additional servers and rapidly set them up as storage servers. We moved data from the SAN to these servers over the 3-4 days after the outage and stabilised our system. These servers are running independently (unreplicated) but are being backed up on a continuous basis. This is of course only good as an interim setup whilst we finalise a long term solution.
Our replicated pair storage architecture performed well up until the point of stress. At this point the system became slow and, along with other expected benefits, prompted the move to the SAN system. Given the SAN is not viable at the moment we have decided to evolve the original solution and are setting up a lightly-loaded multiple redundant pair system:
Network Diagram of Multiple Replicated Pairs
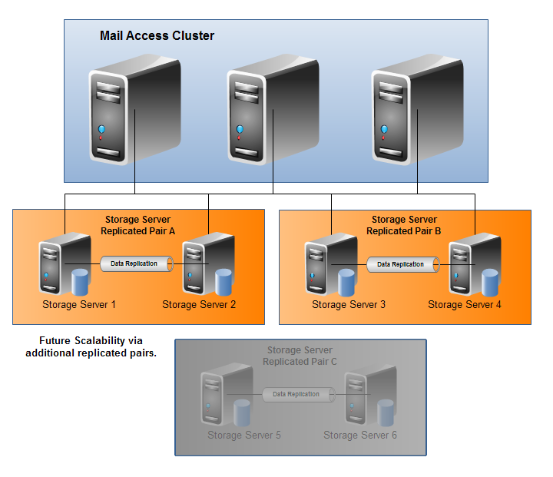
This appears to be a relatively simple improvement to the original system and on the surface it is. Underneath however we will be introducing some more advanced configurations such as increasing the number of slices but keeping them small for faster restore and investigating some, now-mature, automatic failover functionality that would reduce the downtime visible to users to a few seconds. There is also scope for combining some of the mail access cluster functions into the storage servers themselves to further increase performance. These will be investigated in due course.
In addition we will be adding additional capacity at regular intervals and well before any load related issues are introduced. Many of our past issues with our NFS mounts were related to the storage subsystem unable to keep pace with the number of storage read/write requests. A lightly loaded storage server will not suffer from these bottlenecks.
We will also be investing in redundant infrastructure where possible - in particular looking to double up on power feeds and network connections. Last night’s brief power outage, affecting two out of three of our webmail servers, illustrated the importance of this.
These improvements are being worked on every day and will take a number of weeks to finalise. In implementing them we will do our very best to ensure that any impact on your day-to-day use of the system is avoided. Where necessary, we will schedule essential maintenance works to be carried out during off-peak evening hours and would appreciate your understanding.
I hope this brief gives you reasonable assurance that we are working as hard as we can to move on from the negative events of the last two weeks. We are certainly keen to avoid having to repeat the experience ourselves!
To close, I am keen to share that we have been working hard on a couple of exciting projects which will be back on course once we have stabilised service. These include a much upgraded webmail interface and we will release a preview-beta to you as soon as we have the basic functionality implemented. In our members’ survey many of you have commented how the number one thing you want improved is speed and responsiveness. This new interface has been designed with that in mind.
Thank you again for your understanding and patience. With these improvements implemented, I look forward to much calmer sailing ahead.
Faithfully,

Daniel Watts
Managing Director